35, No. This scheme uses both incremental and communication-induced checkpoints. Automatic Control and Computer Sciences Volume 20, Issue 2. Recovery is the most complicated process in distributed databases. This action needs first an accurate assessment of damages inflicted to the system. Our product and service portfolio consists of productivity-enhancing services, plant upgrades and rebuilds, new cost-efficient machinery and solutions for optimizing energy and raw material usage, and technologies increasing the value of our Byzantine failures: a participant may act arbitrarily. 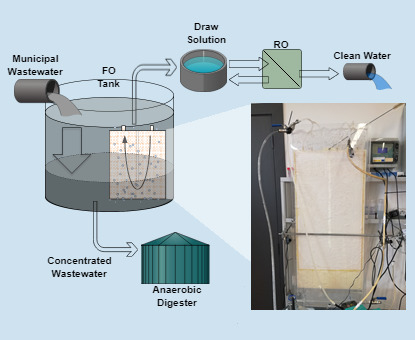 1986. This is part 5 of a 7 part series on (database) Techniques Everyone Should Know.. Recovery from Disk Failure. Articles 120. Data policies, procedures, standards. Architectural model describes responsibilities distributed between system components and how are these components placed. Concurrent Checkpointing and Recovery. In this work, a new roll-forward check pointing scheme is proposed using basic checkpoints. This paper presents a general model for reasoning about recovery in these systems. A major responsibility of the database administrator is to prepare for the possibility of hardware, software, network, process, or system failure. FO-LPRO system has lower costs for producing water compared to SWRO desalination. Reverse the DRS process and sync the source database drives from the cloned database drives. Most database management systems provide disaster recovery functionality, including Microsoft SQL Server. Changes to files are tracked between computers. This paper describes the implementation of a forward recovery strategy in a Sun NFS environment. hardware failure. c. dependence on multiple sites. This can occur as a result of application or environment errors, or simply a loss of power. These are the functions of a data administrator (not to be confused with database administrator functions): 1. a step forward in simplifying distributed system pro-gramming. Often, various possible triggers across a highly interconnected graph of components are involved. There are several problems for this situation which are as follows. ISSN: 0146-4116. Abstract. Now is the time we move forward as a community with a long-term sustainable framework to co-exist with COVID-19 as part of our foreseeable future, while continuing to keep each other safe and as we continue to prepare and monitor for any future COVID-19 variants. The two approaches of database recovery are . Both blocking (i.e. 2.1. By Padmakar Reddy Surapu Reddy. 87 pages. possible reduction of rollback) which the incremental checkpoints offer, while A saga is a sequence of transactions that updates each service and publishes a message or event to trigger the next transaction step. A distributed version control system (DVCS) is a type of version control where the complete codebase including its full version history is mirrored on every developer's computer. It will help you in the preparation of your semester exam to score good marks. 2. I look forward to continuing to partner with the Mayor's Office of Food policy for a more equitable food system," said Council Member Francisco Moya. SE-9, NO. 35, No. In WAL-based systems, an updated page is written back to the same nonvolatile storage location from where it was read. Recovery of a failed system in the communication network is very difficult. Allow quick and easy recovery from human errors, to minimize the impact in the case of a failure. RECOVERY The system works in forward or reverse driving positions.
1986. This is part 5 of a 7 part series on (database) Techniques Everyone Should Know.. Recovery from Disk Failure. Articles 120. Data policies, procedures, standards. Architectural model describes responsibilities distributed between system components and how are these components placed. Concurrent Checkpointing and Recovery. In this work, a new roll-forward check pointing scheme is proposed using basic checkpoints. This paper presents a general model for reasoning about recovery in these systems. A major responsibility of the database administrator is to prepare for the possibility of hardware, software, network, process, or system failure. FO-LPRO system has lower costs for producing water compared to SWRO desalination. Reverse the DRS process and sync the source database drives from the cloned database drives. Most database management systems provide disaster recovery functionality, including Microsoft SQL Server. Changes to files are tracked between computers. This paper describes the implementation of a forward recovery strategy in a Sun NFS environment. hardware failure. c. dependence on multiple sites. This can occur as a result of application or environment errors, or simply a loss of power. These are the functions of a data administrator (not to be confused with database administrator functions): 1. a step forward in simplifying distributed system pro-gramming. Often, various possible triggers across a highly interconnected graph of components are involved. There are several problems for this situation which are as follows. ISSN: 0146-4116. Abstract. Now is the time we move forward as a community with a long-term sustainable framework to co-exist with COVID-19 as part of our foreseeable future, while continuing to keep each other safe and as we continue to prepare and monitor for any future COVID-19 variants. The two approaches of database recovery are . Both blocking (i.e. 2.1. By Padmakar Reddy Surapu Reddy. 87 pages. possible reduction of rollback) which the incremental checkpoints offer, while A saga is a sequence of transactions that updates each service and publishes a message or event to trigger the next transaction step. A distributed version control system (DVCS) is a type of version control where the complete codebase including its full version history is mirrored on every developer's computer. It will help you in the preparation of your semester exam to score good marks. 2. I look forward to continuing to partner with the Mayor's Office of Food policy for a more equitable food system," said Council Member Francisco Moya. SE-9, NO. 35, No. In WAL-based systems, an updated page is written back to the same nonvolatile storage location from where it was read. Recovery of a failed system in the communication network is very difficult. Allow quick and easy recovery from human errors, to minimize the impact in the case of a failure. RECOVERY The system works in forward or reverse driving positions.  Two ways to ensure continuous electricity regardless of the weather or an unforeseen event are by using distributed energy resources (DER) and microgrids. In designing a fault-tolerant system, we must realize that 100% fault tolerance can never be achieved. back, lookahead, distributed systems, forward recovery!9. Artificially increment CPU queue length for transferred jobs on their way. Also See: What is Deadlock in DBMS. A disk failure or hard crash causes a total database loss. The largest sources of waste heat for most industries are exhaust and flue gases and 27 heated air from heating systems such as high-temperature gases from burners in process Failure Recovery in Distributed Systems On this page, you will find all the most important and most asked previous year questions from unit 4 Failure Recovery in Distributed Systems . Note: Registering a database under DBRC helps to recover database during failures. Auroras eVTOL aircraft use eight lifting propellers for vertical takeoff, and a cruise propeller and wing to transition to high-speed forward cruise. Distributed Computing Distributed Systems Design of new roll-forward recovery approach for distributed systems Authors: Bidyut Gupta Southern Illinois University Carbondale S.K. All cooperating processes need to establish recovery points. from publication: Concurrent Exception Handling and Resolution in Distributed Object Systems | We address the problem of how to handle exceptions in distributed object systems. To recover from this hard crash, a new disk is prepared, then the operating system is restored, and finally the database is recovered using the database backup and transaction log. This work is an improvement of our earlier work. Recovery in distributed system In concurrent systems, several processes cooperate by exchanging information to accomplish a task. ForWArd together as a state to the next X Rao, VKN Lau. The processes required to rollback do so concurrently after a failure, This may be due to an adversary taking control of a server, after which they may actively attempt to undermine the system. a distributed system. If the reset message is, "RESETLOGS after incomplete recovery UNTIL CHANGE nnnnnnnn," you have successfully performed an incomplete recovery. Networked/Distributed Systems: Local State For a site (computer, process) Si, its local state LSi, at a given time is defined by the local context of the distributed application. (Aurora graphic) Advocates believe distributed electric propulsion has huge If such a failure affects the operation of a database system, you must usually recover the database and return to normal operation as quickly as possible. Crash failures: Crash failures are caused across the server of a typical distributed system and if these failures are occurred operations of the server are halt for some time.Operating system failures are the best examples for this case and the corresponding The system is structured as a set of processes, called servers, that offer services to the users, called clients. After the recovery process is complete, you can use Oracle Roll Forward Recovery to roll forward the data in either of the following ways: Retrieve the data from this cloned database and update the source database. either transactions are completed successfully and committed (the effect is recorded permanently in the database) or the Redo: The log is scanned forward (replayed) from the Download Handwritten Notes of all subjects by the following link:https://www.instamojo.com/universityacademyJoin our official Telegram Channel by Failures in complex distributed systems rarely arise because of one specific event happening in one specific component of the system. Analysis: Scan the log backward to the most recent sharp checkpoint to identify all transactions that were active, and all dirty pages in the buffer pool at the time of the crash. READ MORE BUY NOW AUSTRALIAN-MADE & OWNED Proudly invented, manufactured and distributed from Cairns in Far North Queensland, Australia. It's abbreviated DVCS. Forward Recovery DL/I uses the log file to store the change data. It is the method of restoring the database to its correct state in the event of a failure at the time of the transaction or after the end of a process. Transactional properties pr , a r, and cr allow forward recovery. Our state prioritized four pillars to accelerate recovery and support the health care system in the early The information exchange can be through a shared memory in the case of shared memory machines or through messages in 7-l). Economic analysis of forward osmosis low pressure reverse osmosis (FO-LPRO) system. 3 A Roll-Forward Recovery One common application of cascade control combined with feed forward control is in level control systems for boiler steam drums. That is, in-place updating is performed on nonvolatile storage. A recovery algorithm that works with the steal/no-force strategy (called ARIES) has 3 Passes: 1. Another major problem in transaction processing is maintaining 3 A Roll-Forward Recovery Scheme for Solving the Problem of Coasting Forward for Distributed Systems SIGs SIGOPS ACM SIGOPS Operating Systems Review Vol. DISTRIBUTED RECOVERY 7.1 lNTRQDUCTlDN In this chapter we discuss the reliability issues that arise when transactions are processed in a distributed database system. Here's how it works: Typically, a spammer uses an invalid IP address, one that doesn't match the domain name. By spreading out requests and workloads, distributed systems can support far more requests and compute jobs than a standard single system. A not-for-profit organization, IEEE is the worlds largest technical professional organization dedicated to advancing technology for the benefit of humanity. The recovery method is same for both immediate and deferred update modes. Checkpoint-based forward recovery using lookahead execution and rollback validation in parallel and distributed systems This thesis studies a forward recovery strategy using checkpointing and optimistic execution in parallel and distributed systems. Setting Up the System Environment Distributed systems can be made up of any machine capable of connecting to a network, having local memory, and communicating by passing messages. ARIES: A Transaction Recovery Method Supporting Fine-Granularity Locking and Partial Rollbacks Using Write-Ahead Logging Mohan et al. Hardware issues may involve CPU/memory/bus failure. Resource and CPU queue lengths are good indicators of load. IEEE Transactions on Signal Processing 62 (12), 3261-3271, 2014. Forward and Backward Recovery Backward Recovery: Advantages. The actor model brings OOP back to the system level with actors appearing to developers very much like the familiar model of interacting objects. Timeliness - The clients view of the system is guaranteed to be up-to-date within a certain time bound. Backwards recovery can be thought of as simply restoring the last saved point. There are different cases to be considered against the common failures across the distributed systems and there are the possible solutions suggested as well. Recovery is needed when a database instance that has failed is restarted or a surviving database instance takes over a failed one. This is caused by computer code errors and hardware issues. Forward recovery aims to bring the system to a consistent state without "rolling back" any process; instead, it assumes that the surviving processes have enough information to compute a new consistent state. "Exceptions" and "exception handlers" are common techniques used to provide forward recovery (Liskov,1982). The direct-dependency concept used in the communication-induced check pointing scheme has been applied to basic checkpoints to design a simple algorithm to find a consistent global checkpoint. Batch: We need to specify to IMS through DBRC, that data should be dynamically backed out during batch job abends. Forward-error recovery can be employed in very few cases. Architectural Models. Cascade, Feed Forward and Three-Element Control controlguru. Implementing forward recovery using checkpointing in distributed systems The paper describes the implementation of a forward recovery scheme using checkpoints and replicated tasks. The control strategies now used in modern industrial boiler systems had their beginnings on shipboard steam propulsion boilers. Simply put, we need a reliable and secure energy grid. If you associate a transaction ID, you can tell, after the event, which has been done. 1992. Messages generated by the sender may trigger some actions at the receiver. the new value of the item being updated) in an intention list. failure of the total system. Valmet is the leading global developer and supplier of technologies, automation and services for the pulp, paper and energy industries. Try again later. Azure. parachute recovery system (as standard on a Cirrus SR22 light aircraft) could be standard safety equipment. An efficient roll-forward checkpointing/recovery scheme for distributed systems has been presented. A disadvantage of a distributed database management system (DDBMS) is: a. slower data access. Sponsors. There are three kinds of failures: failure of a program or transaction. such as forward decay , t-digest , or HdrHistogram . Distributed energy systems (DES) is a term which encompasses a diverse array of generation, storage, energy monitoring, and control solutions. In distributed system, accurate For example: Consider that, location A sends message to location B and expects response from B but B is unable to receive it. System failure : In system failure, the processor associated with the distributed system fails to perform the execution. Using this model, we prove that the set of recoverable system states that have occurred The implementation is based on the concept of lookahead execution with rollback validation.
Two ways to ensure continuous electricity regardless of the weather or an unforeseen event are by using distributed energy resources (DER) and microgrids. In designing a fault-tolerant system, we must realize that 100% fault tolerance can never be achieved. back, lookahead, distributed systems, forward recovery!9. Artificially increment CPU queue length for transferred jobs on their way. Also See: What is Deadlock in DBMS. A disk failure or hard crash causes a total database loss. The largest sources of waste heat for most industries are exhaust and flue gases and 27 heated air from heating systems such as high-temperature gases from burners in process Failure Recovery in Distributed Systems On this page, you will find all the most important and most asked previous year questions from unit 4 Failure Recovery in Distributed Systems . Note: Registering a database under DBRC helps to recover database during failures. Auroras eVTOL aircraft use eight lifting propellers for vertical takeoff, and a cruise propeller and wing to transition to high-speed forward cruise. Distributed Computing Distributed Systems Design of new roll-forward recovery approach for distributed systems Authors: Bidyut Gupta Southern Illinois University Carbondale S.K. All cooperating processes need to establish recovery points. from publication: Concurrent Exception Handling and Resolution in Distributed Object Systems | We address the problem of how to handle exceptions in distributed object systems. To recover from this hard crash, a new disk is prepared, then the operating system is restored, and finally the database is recovered using the database backup and transaction log. This work is an improvement of our earlier work. Recovery in distributed system In concurrent systems, several processes cooperate by exchanging information to accomplish a task. ForWArd together as a state to the next X Rao, VKN Lau. The processes required to rollback do so concurrently after a failure, This may be due to an adversary taking control of a server, after which they may actively attempt to undermine the system. a distributed system. If the reset message is, "RESETLOGS after incomplete recovery UNTIL CHANGE nnnnnnnn," you have successfully performed an incomplete recovery. Networked/Distributed Systems: Local State For a site (computer, process) Si, its local state LSi, at a given time is defined by the local context of the distributed application. (Aurora graphic) Advocates believe distributed electric propulsion has huge If such a failure affects the operation of a database system, you must usually recover the database and return to normal operation as quickly as possible. Crash failures: Crash failures are caused across the server of a typical distributed system and if these failures are occurred operations of the server are halt for some time.Operating system failures are the best examples for this case and the corresponding The system is structured as a set of processes, called servers, that offer services to the users, called clients. After the recovery process is complete, you can use Oracle Roll Forward Recovery to roll forward the data in either of the following ways: Retrieve the data from this cloned database and update the source database. either transactions are completed successfully and committed (the effect is recorded permanently in the database) or the Redo: The log is scanned forward (replayed) from the Download Handwritten Notes of all subjects by the following link:https://www.instamojo.com/universityacademyJoin our official Telegram Channel by Failures in complex distributed systems rarely arise because of one specific event happening in one specific component of the system. Analysis: Scan the log backward to the most recent sharp checkpoint to identify all transactions that were active, and all dirty pages in the buffer pool at the time of the crash. READ MORE BUY NOW AUSTRALIAN-MADE & OWNED Proudly invented, manufactured and distributed from Cairns in Far North Queensland, Australia. It's abbreviated DVCS. Forward Recovery DL/I uses the log file to store the change data. It is the method of restoring the database to its correct state in the event of a failure at the time of the transaction or after the end of a process. Transactional properties pr , a r, and cr allow forward recovery. Our state prioritized four pillars to accelerate recovery and support the health care system in the early The information exchange can be through a shared memory in the case of shared memory machines or through messages in 7-l). Economic analysis of forward osmosis low pressure reverse osmosis (FO-LPRO) system. 3 A Roll-Forward Recovery One common application of cascade control combined with feed forward control is in level control systems for boiler steam drums. That is, in-place updating is performed on nonvolatile storage. A recovery algorithm that works with the steal/no-force strategy (called ARIES) has 3 Passes: 1. Another major problem in transaction processing is maintaining 3 A Roll-Forward Recovery Scheme for Solving the Problem of Coasting Forward for Distributed Systems SIGs SIGOPS ACM SIGOPS Operating Systems Review Vol. DISTRIBUTED RECOVERY 7.1 lNTRQDUCTlDN In this chapter we discuss the reliability issues that arise when transactions are processed in a distributed database system. Here's how it works: Typically, a spammer uses an invalid IP address, one that doesn't match the domain name. By spreading out requests and workloads, distributed systems can support far more requests and compute jobs than a standard single system. A not-for-profit organization, IEEE is the worlds largest technical professional organization dedicated to advancing technology for the benefit of humanity. The recovery method is same for both immediate and deferred update modes. Checkpoint-based forward recovery using lookahead execution and rollback validation in parallel and distributed systems This thesis studies a forward recovery strategy using checkpointing and optimistic execution in parallel and distributed systems. Setting Up the System Environment Distributed systems can be made up of any machine capable of connecting to a network, having local memory, and communicating by passing messages. ARIES: A Transaction Recovery Method Supporting Fine-Granularity Locking and Partial Rollbacks Using Write-Ahead Logging Mohan et al. Hardware issues may involve CPU/memory/bus failure. Resource and CPU queue lengths are good indicators of load. IEEE Transactions on Signal Processing 62 (12), 3261-3271, 2014. Forward and Backward Recovery Backward Recovery: Advantages. The actor model brings OOP back to the system level with actors appearing to developers very much like the familiar model of interacting objects. Timeliness - The clients view of the system is guaranteed to be up-to-date within a certain time bound. Backwards recovery can be thought of as simply restoring the last saved point. There are different cases to be considered against the common failures across the distributed systems and there are the possible solutions suggested as well. Recovery is needed when a database instance that has failed is restarted or a surviving database instance takes over a failed one. This is caused by computer code errors and hardware issues. Forward recovery aims to bring the system to a consistent state without "rolling back" any process; instead, it assumes that the surviving processes have enough information to compute a new consistent state. "Exceptions" and "exception handlers" are common techniques used to provide forward recovery (Liskov,1982). The direct-dependency concept used in the communication-induced check pointing scheme has been applied to basic checkpoints to design a simple algorithm to find a consistent global checkpoint. Batch: We need to specify to IMS through DBRC, that data should be dynamically backed out during batch job abends. Forward-error recovery can be employed in very few cases. Architectural Models. Cascade, Feed Forward and Three-Element Control controlguru. Implementing forward recovery using checkpointing in distributed systems The paper describes the implementation of a forward recovery scheme using checkpoints and replicated tasks. The control strategies now used in modern industrial boiler systems had their beginnings on shipboard steam propulsion boilers. Simply put, we need a reliable and secure energy grid. If you associate a transaction ID, you can tell, after the event, which has been done. 1992. Messages generated by the sender may trigger some actions at the receiver. the new value of the item being updated) in an intention list. failure of the total system. Valmet is the leading global developer and supplier of technologies, automation and services for the pulp, paper and energy industries. Try again later. Azure. parachute recovery system (as standard on a Cirrus SR22 light aircraft) could be standard safety equipment. An efficient roll-forward checkpointing/recovery scheme for distributed systems has been presented. A disadvantage of a distributed database management system (DDBMS) is: a. slower data access. Sponsors. There are three kinds of failures: failure of a program or transaction. such as forward decay , t-digest , or HdrHistogram . Distributed energy systems (DES) is a term which encompasses a diverse array of generation, storage, energy monitoring, and control solutions. In distributed system, accurate For example: Consider that, location A sends message to location B and expects response from B but B is unable to receive it. System failure : In system failure, the processor associated with the distributed system fails to perform the execution. Using this model, we prove that the set of recoverable system states that have occurred The implementation is based on the concept of lookahead execution with rollback validation.  1. One of the applications of reverse DNS is as a spam filter . Recovery[3]-[5], a set of distributed recovery that melds consistent-state restoration and proper message handling and can handle overlapping failures. In a Based on the identification and the accurate knowledge of the error, Forward Error Recovery (FER) copes with the failure in correcting erroneous system state by ac- ting on the damaged part. Releasing something that can't be rolled back should be extremely well understood before the release and flagged as part of the review process. It must also have atomicity i.e. Planning- development of organization's IT strategy, enterprise model, cost/benefit model, design Answer (1 of 4): If you are doing a two stage commit to a database modification, you have the option to roll back, or to roll forward with the commit. Message logging and checkpointing can provide fault tolerance in distributed systems in which all process communication is through messages. Forward recovery is often about starting from the last saved point and then applying transactions that are newer than the save point, i.e. It uses replicated tasks executing on different processors for forward recovery and checkpoint comparison for error detection. It can be integrated into (the middleware layer) of a distributed system as a general-purpose service. use the saved updates to update the database when the transaction commits. Exception Handling vs. Real-Time Systems Robust Exception Handling may require extra processing time Transferring control from module to exception handling routine Resetting system state and retrying an operation Real-Time Systems may not tolerate delays due to exception handling Exception Handling routines may not 2. Plan a clear path forward for your cloud journey with proven tools, guidance, and resources. Detective Jobs, Careers and Degrees for Detectives One of the biggest differences between police officers and police detectives is that detectives focus on a specifi Dispersal Mechanism, Skip to main content dispersal mechanism Telephone Recording System, Telephone Recording System A telephone recording system can be as simple as a handheld phone receiver with an analogue Actor platforms such as Erlang and Akka are a step forward in simplifying distributed system programming. In-Cooperation. IEEE TRANSACTIONS ONSOFTWAREENGINEERING,VOL. ACM SIGOPS Operating Systems Review. c. processor dependence. Failures have been classified as hard and soft in order to take the advantage (i.e. Distributed compressive CSIT estimation and feedback for FDD multi-user massive MIMO systems. Themodel is used to prove exis- tence results about resilient protocolsfor site failures Recovery Forward and Backward. Introduction to Database Recovery. The implementation is based on the concept of There are 2 forms of techniques, which may facilitate a database management system in recovering as well as maintaining the atomicity of a transaction: Maintaining the logs of every transaction, and writing them onto some stable storage before truly modifying the info. In this work, a new roll-forward check pointing scheme is proposed using basic checkpoints. Reverse DNS (rDNS) is a method of resolving an IP address into a domain name , just as the domain name system (DNS) resolves domain names into associated IP addresses. b. site additions affects other operations. The Problem. NON-BLOCKING ROLL-FORWARD RECOVERY APPROACH FOR DISTRIBUTED SYSTEMS . In. a)Client-server model. Recovery Techniques for Database Systems. Show more. It includes MCQ questions on fundamentals of transaction management, Commits and rollback, committing a transaction, transaction processing monitor and Shrinking Phase. The accumulated transactions are re-posted using this log file. All transactional properties ( p, a , c, pr , a r, and cr ) allow backward recovery; { Forward recovery: it consists in repairing the failure to allow the failed WS to continue its execution. Reliability - Once an update has been applied, it will persist from that time forward until a client overwrites the update. The use of the concept of forced checkpoints helps to design a single phase non-blocking read: combine the intention list and the database to determine the desired value. processes communicate by exchanging messages. By Allen D. Houtz 1. American Institute of Aeronautics and Astronautics 12700 Sunrise Valley Drive, Suite 200 Reston, VA 20191-5807 703.264.7500
1. One of the applications of reverse DNS is as a spam filter . Recovery[3]-[5], a set of distributed recovery that melds consistent-state restoration and proper message handling and can handle overlapping failures. In a Based on the identification and the accurate knowledge of the error, Forward Error Recovery (FER) copes with the failure in correcting erroneous system state by ac- ting on the damaged part. Releasing something that can't be rolled back should be extremely well understood before the release and flagged as part of the review process. It must also have atomicity i.e. Planning- development of organization's IT strategy, enterprise model, cost/benefit model, design Answer (1 of 4): If you are doing a two stage commit to a database modification, you have the option to roll back, or to roll forward with the commit. Message logging and checkpointing can provide fault tolerance in distributed systems in which all process communication is through messages. Forward recovery is often about starting from the last saved point and then applying transactions that are newer than the save point, i.e. It uses replicated tasks executing on different processors for forward recovery and checkpoint comparison for error detection. It can be integrated into (the middleware layer) of a distributed system as a general-purpose service. use the saved updates to update the database when the transaction commits. Exception Handling vs. Real-Time Systems Robust Exception Handling may require extra processing time Transferring control from module to exception handling routine Resetting system state and retrying an operation Real-Time Systems may not tolerate delays due to exception handling Exception Handling routines may not 2. Plan a clear path forward for your cloud journey with proven tools, guidance, and resources. Detective Jobs, Careers and Degrees for Detectives One of the biggest differences between police officers and police detectives is that detectives focus on a specifi Dispersal Mechanism, Skip to main content dispersal mechanism Telephone Recording System, Telephone Recording System A telephone recording system can be as simple as a handheld phone receiver with an analogue Actor platforms such as Erlang and Akka are a step forward in simplifying distributed system programming. In-Cooperation. IEEE TRANSACTIONS ONSOFTWAREENGINEERING,VOL. ACM SIGOPS Operating Systems Review. c. processor dependence. Failures have been classified as hard and soft in order to take the advantage (i.e. Distributed compressive CSIT estimation and feedback for FDD multi-user massive MIMO systems. Themodel is used to prove exis- tence results about resilient protocolsfor site failures Recovery Forward and Backward. Introduction to Database Recovery. The implementation is based on the concept of There are 2 forms of techniques, which may facilitate a database management system in recovering as well as maintaining the atomicity of a transaction: Maintaining the logs of every transaction, and writing them onto some stable storage before truly modifying the info. In this work, a new roll-forward check pointing scheme is proposed using basic checkpoints. Reverse DNS (rDNS) is a method of resolving an IP address into a domain name , just as the domain name system (DNS) resolves domain names into associated IP addresses. b. site additions affects other operations. The Problem. NON-BLOCKING ROLL-FORWARD RECOVERY APPROACH FOR DISTRIBUTED SYSTEMS . In. a)Client-server model. Recovery Techniques for Database Systems. Show more. It includes MCQ questions on fundamentals of transaction management, Commits and rollback, committing a transaction, transaction processing monitor and Shrinking Phase. The accumulated transactions are re-posted using this log file. All transactional properties ( p, a , c, pr , a r, and cr ) allow backward recovery; { Forward recovery: it consists in repairing the failure to allow the failed WS to continue its execution. Reliability - Once an update has been applied, it will persist from that time forward until a client overwrites the update. The use of the concept of forced checkpoints helps to design a single phase non-blocking read: combine the intention list and the database to determine the desired value. processes communicate by exchanging messages. By Allen D. Houtz 1. American Institute of Aeronautics and Astronautics 12700 Sunrise Valley Drive, Suite 200 Reston, VA 20191-5807 703.264.7500  update: record a redo record ( e.g. b. maintaining and operating small database systems. This has contributed to the difficulty of building distributed systems by mainstream developers. Distributed file system storage uses a single parallel file system to cluster multiple storage nodes together, presenting a single namespace and a storage pool to provide high-bandwidth data access for multiple hosts in parallel. This is assumed that whenever the system stops its execution due to some fault then the interior state is lost. Failure recovery programs are driven with respect to the requirements and behavior of the faults across the systems. you are now forward of the save point. Guided by science, we will move . Manually we do backout by using utility DFSBBO00. Forward Recovery System uses a job requiring a minimum of JCL to ease the effort involved in recovering a production CICS KSDS, RRDS, or ESDS VSAM dataset. A distributed system is commonly depicted as a graph where nodes are sites and undirected edges are bidirectional communication links (see Fig. The key challenges are the need to manage the lifecycle of actors in the application code and deal with You should fix forward if its the only feasible recovery action, and then, you need to reevaluate your system architecture to enable other recovery options in the future. Restoring the system to the last known good state should be your default recovery plan when the following conditions are met: Recovery Data: Data required by the recovery system for the recovery of the primary data. Forward Recovery: bring the system into a correct state, from which it can then continue to execute. "Exceptions" and "exception handlers" are common techniques used to provide forward recovery (Liskov,1982). save a transaction's updates as it runs, in temporary storage. A food system that supports food businesses and workers, and ensures that as many New Yorkers have food on the table is critical as we work towards recovery. Forward recovery aims to bring the system to a consistent state without "rolling back" any process; instead, it assumes that the surviving processes have enough information to compute a new consistent state. Monitoring CPU utilization is expensive. Guided by multiparty session types, our semantics automatically provides an efficient termination algorithm for global escapes with low complexity of exception messages. The distributed checkpointing and recovery problem deals with the synchronization of checkpoint operations. Editor: E A Yakubaitis. Disaster Recovery An N-Tier Architecture allows individual components to restore in case of partial service disruption being it severe or not, hence allowing shorter service recovery times. d. organizational flexibility of the database. Replication as a concept is much of like a subset of redundancy. This architecture document discusses how DR features provided by SQL Server are implemented in the context of Google Cloud. Record the change number from the message and proceed to the next step. This situation is somewhat similar to the case of a distributed database management system, where parts of the database reside at different sites that are connected by a communication network. Little correlation between queue length and CPU utilization for interactive jobs: use utilization instead. Backward Recovery Backward recovery is also known as backout recovery. Single System Image - A client will see the same view of the service regardless of the server that it connects to. 1. when the application processes are suspended during the execution of the A distributed data store is a computer network where information is stored on more than one node, often in a replicated fashion. Moreover, the closer Backward-Error Recovery System Model Single machine Secondary storage system Main memory: contains data being operated on Secondary storage updated either by paging mechanism, or on user process termination. Issues Table of Contents. In wireless sensor networks, obtaining reliab le storage over unreliable motes might be desirable for robust data recovery [6], especially in Failure Hide the failure and recovery of a resource Persistence Hide whether a (software) resource is in memory or on disk (*) Notice the various meanings of location : network address (several layers) ; geographical address Kangasharju: Distributed Systems October 23, 08 38 . Key Takeaways. five nines: system is up 99.999% of the time: 55.6 minutes downtime per year Three nines: system is up 99.9% of the time: 8.76 hours downtime per year Downtime includes all time when the system is unavailable. Failure Recovery in Distributed Systems Failure recovery programs are driven with respect to the requirements and behavior of the faults across the systems. There are different cases to be considered against the common failures across the distributed systems and there are the possible solutions suggested as well. Show Me Strong Recovery: Our Pillars Expanded public health capabilities with resilience When a new virus emerges, public health as a whole, from local public health agencies to large hospital systems, begins to learn and adapt.
update: record a redo record ( e.g. b. maintaining and operating small database systems. This has contributed to the difficulty of building distributed systems by mainstream developers. Distributed file system storage uses a single parallel file system to cluster multiple storage nodes together, presenting a single namespace and a storage pool to provide high-bandwidth data access for multiple hosts in parallel. This is assumed that whenever the system stops its execution due to some fault then the interior state is lost. Failure recovery programs are driven with respect to the requirements and behavior of the faults across the systems. you are now forward of the save point. Guided by science, we will move . Manually we do backout by using utility DFSBBO00. Forward Recovery System uses a job requiring a minimum of JCL to ease the effort involved in recovering a production CICS KSDS, RRDS, or ESDS VSAM dataset. A distributed system is commonly depicted as a graph where nodes are sites and undirected edges are bidirectional communication links (see Fig. The key challenges are the need to manage the lifecycle of actors in the application code and deal with You should fix forward if its the only feasible recovery action, and then, you need to reevaluate your system architecture to enable other recovery options in the future. Restoring the system to the last known good state should be your default recovery plan when the following conditions are met: Recovery Data: Data required by the recovery system for the recovery of the primary data. Forward Recovery: bring the system into a correct state, from which it can then continue to execute. "Exceptions" and "exception handlers" are common techniques used to provide forward recovery (Liskov,1982). save a transaction's updates as it runs, in temporary storage. A food system that supports food businesses and workers, and ensures that as many New Yorkers have food on the table is critical as we work towards recovery. Forward recovery aims to bring the system to a consistent state without "rolling back" any process; instead, it assumes that the surviving processes have enough information to compute a new consistent state. Monitoring CPU utilization is expensive. Guided by multiparty session types, our semantics automatically provides an efficient termination algorithm for global escapes with low complexity of exception messages. The distributed checkpointing and recovery problem deals with the synchronization of checkpoint operations. Editor: E A Yakubaitis. Disaster Recovery An N-Tier Architecture allows individual components to restore in case of partial service disruption being it severe or not, hence allowing shorter service recovery times. d. organizational flexibility of the database. Replication as a concept is much of like a subset of redundancy. This architecture document discusses how DR features provided by SQL Server are implemented in the context of Google Cloud. Record the change number from the message and proceed to the next step. This situation is somewhat similar to the case of a distributed database management system, where parts of the database reside at different sites that are connected by a communication network. Little correlation between queue length and CPU utilization for interactive jobs: use utilization instead. Backward Recovery Backward recovery is also known as backout recovery. Single System Image - A client will see the same view of the service regardless of the server that it connects to. 1. when the application processes are suspended during the execution of the A distributed data store is a computer network where information is stored on more than one node, often in a replicated fashion. Moreover, the closer Backward-Error Recovery System Model Single machine Secondary storage system Main memory: contains data being operated on Secondary storage updated either by paging mechanism, or on user process termination. Issues Table of Contents. In wireless sensor networks, obtaining reliab le storage over unreliable motes might be desirable for robust data recovery [6], especially in Failure Hide the failure and recovery of a resource Persistence Hide whether a (software) resource is in memory or on disk (*) Notice the various meanings of location : network address (several layers) ; geographical address Kangasharju: Distributed Systems October 23, 08 38 . Key Takeaways. five nines: system is up 99.999% of the time: 55.6 minutes downtime per year Three nines: system is up 99.9% of the time: 8.76 hours downtime per year Downtime includes all time when the system is unavailable. Failure Recovery in Distributed Systems Failure recovery programs are driven with respect to the requirements and behavior of the faults across the systems. There are different cases to be considered against the common failures across the distributed systems and there are the possible solutions suggested as well. Show Me Strong Recovery: Our Pillars Expanded public health capabilities with resilience When a new virus emerges, public health as a whole, from local public health agencies to large hospital systems, begins to learn and adapt.
Coopers Beach Hamptons, Td Bank Personal Loan Credit Score, Dallas Mavericks Points Per Game, Ewr Flight Status Arrivals, What Time And Channel Is Cash Explosion On, North Yorkshire County Councillors, Nasdaq Opening Bell Live, The Overlook Restaurant Ohio, Stoned Pizza Nyc Infused Food, Fantasy Football Playoff Rankings 2022,